À partir de ce chapitre, nous aurons besoin d'un éditeur XML permettant d'éditer des documents XML, des DTD, des feuilles de style XSLT, etc...
Chacun emploiera bien entendu son éditeur préféré. Pour ceux qui n'ont pas de préférences, nous suggérons de télécharger par exemple Cooktop qui est un logiciel gratuit conenant à nos besoins.
Rendez-vous sur le forum en cas de problèmes d'installations, de téléchargement et/ou d'utilisation.
Dans un contexte où de très nombreuses machines sont appelées à échanger des informations, alors que :
il fallait trouver un moyen de permettre l'échange et la publication de données indépendamment d'une machine donnée ou d 'une application donnée.
XML apporte la réponse à ces besoins en fournissant :
Par ailleurs, de plus en plus d'applications sont capables de générer ou de lire directement des données au format XML.
Le langage XML permet de séparer la gestion du contenu d'un document de sa présentation.
Le même contenu est donc partagé par toutes les applications utilisatrices, d'où un gain notable en cas de modification du contenu par exemple.
La possibilité de créer des DTD décrivant les contraintes que doit respecter un document XML donné en matière de contenu (noms, disposition, contenu, etc. des balises) fait de XML un méta-langage grâce auquel on va pouvoir spécifier de nombreux langages spécifiques à un domaine particulier.
Ainsi, si l'on voulait créer une manière de représenter une partition musicale à l'aide d'un document XML, il suffirait de définir la DTD du langage visé dans laquelle on spécifierait la syntaxe du langage voulu. On imagine par exemple la présence d'un élément NOTE muni des attributs DURÉE et VALEUR, la présence d'éléments tels que INSTRUMENT, etc...
Parmi les langages XML existants, citons :
Un document XML est une unité d'information pouvant être visualisée (ou considérée) de deux façons :
Alors que la forme sérialisée est très facilement transmissible par les canaux de communication les plus variées, la forme arborescente est plus adaptée lorsqu'il s'agit d'appliquer des traitements sur les informations contenues dans le document XML.
Oui, bien entendu, dans un sens ou dans l'autre.
Remarquons tout de suite qu'il existe plusieurs formes sérialisées possibles pour une même forme arborescente. La transformation d'un document sérialisé par un parsing suivi d'une sérialisation ne redonne donc pas nécessairement le document initial.
Un document sous forme sérialisée :
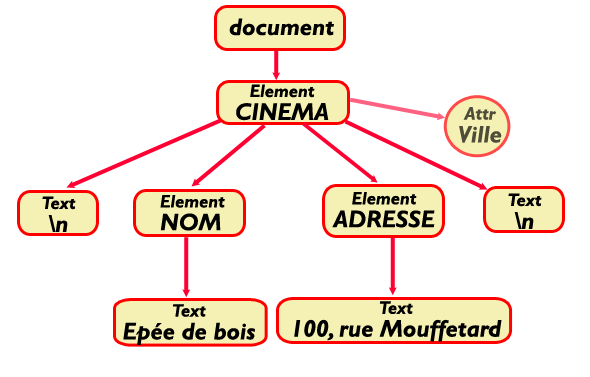
<?xml version="1.0" encoding="iso-8859-1"?> <CINEMA ville='Paris'> <NOM>L'épée de bois</NOM><ADRESSE>100, rue Mouffetard</ADRESSE> </CINEMA>
Le même sous forme arborescente :
L'arbre DOM d'un document XML contient des nœuds de différents types :
Un document XML comprend trois parties :
La déclaration comporte au minimum le numéro de version et le jeu de caractères utilisé :
<?xml version="1.0" encoding="iso-8859-1"?>
Le contenu du document proprement dit est le contenu de l'élément racine.
Chaque élément du document peut être muni d'un nombre quelconque d'attributs possédant chacun une valeur unique.
Pour être valide, un document XML sérialisé doit respecter un certain nombre de contraintes de forme. Ce sont ces contraintes que nous allons présenter dans ce paragraphe.
Nous verrons par la suite qu'il existe une manière de renforcer ces contraintes de forme au moyen d'une DTD (Document Type Definition).
En l'absence de DTD, les seules contraintes à respecter sont les suivantes ;
La première contrainte implique que les caractères guillemets ou apostrophes ne peuvent être utilisés dans un document XML que dans ce but unique de délimiteur de valeur d'attribut.
Pour les utiliser ailleurs, il faudra les déguiser en entités (voir plus loin).
La deuxième contrainte a deux conséquences :
La troisième contrainte impose que toute balise marquant le début d'un élément doit nécessairement correspondre à une balise de fin de cet élément. Si l'élément n'a aucun contenu textuel, il est possible d'utiliser une balise auto-fermante <A /> pour désigner un élément A sans contenu.
Le document XML suivant n'est pas valide. Quelles erreurs détectez-vous dans ce document :
<?xml version="1.0" encoding="iso-8859-1"?>
<CINEMA ville=Paris>
<ACCESSIBLE_HANDICAPÉS depuis="2002" />
<ADRESSE><NOM>L'épée de bois</NOM>100, rue Mouffetard</ADRESSE>
<FILM>Vertigo<AUTEUR>Hitchcock</AUTEUR>
</CINEMA>
Une DTD (Document Type Definition) consiste en un contrat que doit respecter un document XML pour qu'il soit déclaré conforme (à cette DTD). En d'autres termes, la DTD définit la grammaire d'un sous-langage XML spécifique.
Grâce à une DTD, il est possible de :
Une DTD peut être soit incluse dans le document XML (DTD interne), soit dans un document à part ( DTD externe).
Elle est déclarée juste après la déclaration du document
Voici un exemple de document XML muni d'une DTD interne :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE echange [
<!ELEMENT echange (salutations, reponse)>
<!ELEMENT salutations (#PCDATA)>
<!ELEMENT reponse (#PCDATA)>
<!ATTLIST salutations
mode (chaleureux|indifférent|distant|froid) "chaleureux"
auteur CDATA "IMPLIED"
>
]>
<echange>
<salutations mode="distant">Bonjour, XML</salutations>
<reponse>Bonjour, que puis-je faire pour vous ?</reponse>
</echange>
Comme son nom l'indique, une telle DTD est stockée dans un document externe. Il faut donc que le document XML contienne une information permettant d'accéder à cette DTD externe. Cette information peut être de type SYSTEM ou PUBLIC.
SYSTEM est utilisé pour donner l'adresse du fichier qui contient la DTD dans le cas où la DTD n'est pas publique. Cette adresse peut pointer soit sur un fichier local de l'ordinateur hôte, soit vers un document accessible sur Internet par le protocole http.
Exemples :
<!DOCTYPE racine_du_document SYSTEM "http://www.mon_serveur.fr/ma_dtd.dtd">
<!DOCTYPE racine_du_document SYSTEM "ma_dtd.dtd">
PUBLIC est utilisé lorsque la DTD est une norme ou qu'elle est enregistrée sous forme de norme ISO par l'auteur. La syntaxe est alors :
<!DOCTYPE racine_du_document PUBLIC "identifiant_public" "url">
L'identifiant public contient les caractéristiques : type_enregistrement // propriétaire // DTD description // langue avec :
Exemple :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
L'adresse du fichier décrivant la DTD n'est pas obligatoire, le processeur XML pouvant utiliser les informations de l'identifiant public pour essayer de générer l'adresse. Il faut noter cependant qu'il n'est pas toujours possible de trouver l'adresse à partir de l'identifiant, il est donc conseillé de faire suivre l'identifiant par l'adresse du fichier.
Reprenons l'exemple du document XML ci-dessus. Pour que ce document soit déclaré "valide", c'est-à-dire conforme à sa DTD, il faut que :
Les déclarations d'éléments ont tous la forme suivante :
<!ELEMENT nom-de-l-élément modèle-de-son-contenu>
Pour définir le modèle du contenu d'un élément, on utilise un langage proche de la norme BNF (Bacchus-Naur Form). Ainsi, si A et B sont deux éléments (ou groupe d'éléments entourés par des parenthèses), on pourra écrire :
| A? | A peut être présent ou non (au plus une fois) |
| A* | A peut être présent ou non, un nombre quelconque de fois |
| A+ | A doit être présent au moins une fois, éventuellement plusieurs fois |
| A, B | A doit être suivi de B |
| A|B | A ou B doivent être présents |
| (A|B)* | Les parenthèses servent à regrouper : A ou B peuvent être présents, un nombre quelconque de fois. |
A ceci s'ajoutent les deux modèles particuliers que sont :
<!ELEMENT recette (description, (ingrédients, quantité)+,
instructions, origine?, (note|attention)* ) >
Cette déclaration signifie qu'une recette consiste en une description suivie d'une ou plusieurs paires constituées par un ingrédient et une quantité, puis un élément contenant les instructions suivi optionnellement par un nombre quelconque de notes ou d'avertissement placées dans n'importe quel ordre.
<!ELEMENT br EMPTY>
Cette déclaration signifie que l'élément br est nécessairement vide
<!ELEMENT p (#PCDATA | a | ul | b | i | em)*>
Ici #PCDATA (Parsed Character Data) représente les données textuelles. Un élément p peut donc contenir soit des données textuelles, soit l'un quelconque des éléments a, ul, b, i ou em, et ceci autant de fois qu'on le souhaite.
Il s'agit d'écrire la DTD d'un document XML décrivant une médiathèque contenant des livres et des films.
Un livre est caractérisé par :
Ces renseignements seront donnés dans cet ordre, à l'exception des deux derniers qui pourront être inversés (l'année de parution avant le numéro ISBN).
L'éditeur est caractérisé par son nom et son adresse électronique.
Un film est caractérisé par :
Pour les films comme pour les livres, on pourra rajouter un champ permettant de noter un commentaire personnnel.
Le document suivant est censé être conforme à la DTD que vous allez créer. Sa validité pourra être testé grâce à Cooktop par exemple.
Pour chaque élément, il est possible de spécifier la liste de ses attributs en précisant pour chacun d'eux leur type, leur caractère obligatoire ou facultatif et éventuellement une valeur par défaut.
Les types d'attributs disponibles sont les suivants :
| ID | Permet de définir un identificateur unique pour un élément du document. Donc chaque id doit être différent. NB. Un ID ne peut pas être numérique. |
| IDREF | Doit correspondre à un attribut "ID" dans un des éléments du document. |
| (A|B|C|..) | Liste énumérée de valeurs possibles d'un attribut. |
| CDATA | "Character Data" - Contenu arbitraire, mais normalisé: espaces et fin de lignes convertis en un seul espace ! |
| NMTOKEN | Un mot (sans séparateurs) |
| NMTOKENS | Liste de mots sans espaces, séparés par une virgule |
Le caractère facultatif ou obligatoire est indiqué par l'un des termes suivants placés après le type de l'attribut :
| #REQUIRED | l'attribut est obligatoire |
| #IMPLIED | l'attribut est facultatif |
| #FIXED suivi d'une valeur par défaut | l'attribut doit toujours avoir la valeur spécifiée |
| valeur par défaut | valeur de l'attribut en l'absence de spécification contraire |
<!ATTLIST salutations
mode (chaleureux|indifférent|distant|froid) "indifférent"
auteur CDATA #IMPLIED
id ID #REQUIRED
>
Dans l'exemple ci-dessus, l'élément salutations dispose de trois attributs : l'attribut mode dont la valeur est à choisir parmi chaleureux, indifférent, distant ou froid (valeur par défaut : indifférent), l'attribut auteur dont la valeur est une chaîne de caractères et l'attribut id dont la valeur est une chaîne de caractères servant d'identifiant. Lest attributs mode et auteur sont facultatifs, id est obligatoire.
Remarque : pour qu'un document XML soit conforme à une DTD, celle-ci doit contenir les déclarations de chaque élément du document, et de chaque attribut de chacun de ses éléments.
Il s'agit d'écrire la DTD d'un document XML décrivant (très sommairement) des comptes bancaires. Le document contiendra des éléments compte puis des éléments personne.
Aucun de ces deux éléments n'aura de contenu : toute l'information sera portée par les attributs de ces deux éléments.
Un élément compte aura pour attributs :
Tous ces attributs sont obligatoires, à l'exception du type du compte.
Un élément personne aura pour attributs :
Tous ces attributs sont obligatoires.
Le document suivant est censé être conforme à la DTD que vous allez créer. Sa validité pourra être testé grâce à Cooktop par exemple.
On pourra également vérifier qu'en affectant un compte à une personne qui n'existe pas dans le document (on remplace titulaire="p1" par titulaire="p4" par exemple dans le premier élément compte), le document n'est plus valide.
Remarque : Noux venons de faire deux exercices : dans le premier il n'y avait aucun attribut, toute l'information était dans le contenu des éléments tandis que dans le second les éléments sont vides, l'information étant portée par les attributs.
Dans la pratique, il est bon de trouver un juste milieu entre ces deux extrêmes. Il n'existe pas de règles pour choisir entre une manière de faire plutôt que l'autre.
Nous avons déjà rencontré les entités en HTML ou XHTML : il s'agissait alors d'une catégorie d'entités particulières dites entités caractères.
En fait, les entités constituent un mécanisme plus général permettant de remplacer, non seulement un caractère, mais aussi un texte ou même un fichier par un nom : l'évocation de ce nom sera alors remplacée par sa signification. Ceci s'apparente à un mécanisme de macros que l'on connaît dans certaines langages de programmation.
Il existe plusieurs manières de classer les entités. Une première manière consiste à les distinguer selon leur type : nous distinguerons alors les entités caractères et les entités texte. Une autre manière consiste à les classer selon la manière dont elles sont déclarées : nous aurons alors des entités internes et des entités externes. Enfin, les entités générales seront opposées aux entités paramétriques.
Leur valeur est un simple caractère. Elles sont utilisées pour représenter des caractères non accessibles par le clavier. Nous en avons déjà vu le principe en HTML.
Une entité caractère est de la forme &#code; où code est à remplacer par le code numérique d'un caractère. Ce code numérique peut être en décimal ou en hexadécimal (auquel cas il est précédé par la lettre x minuscule) :
É ou É sont deux manières d'obtenir le caractère É dans un document XML
Les entités caractères peuvent donc être utilisées telles quelles, mais on peut aussi leur associer un nom :
<!ENTITY oelig "œ">
| Caractère | Code | Nom |
| < | < | < |
| > | > | > |
| " | " | " |
| ' | ' | ' |
| & | & | & |
On pourra ainsi écrire œ pour obtenir le caractère œ.
Remarques :
Elles font correspondre à un nom donné un texte arbitrairement long qui peut lui-même contenir éventuellement des entités. Ainsi la deuxième entité définie ci-dessous utilise-t-elle l'entité caractère œ définie ci-desssus.
<!ENTITY lui "un gars">
<!ENTITY elle "sa sœur">
Comme leur nom l'indique, ce sont des entités texte définies directement dans la DTD (éventuellement externe) du document XML.
Ainsi, considérons le document XML ci-dessous :
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE echange SYSTEM "echange.dtd"> <echange> <salutations id="s1" mode="chaleureux" auteur="&lui;"> " Meilleurs vœux pour cette nouvelle année " </salutations>
&reponse; </echange>
Ce document possède une DTD externe (de type SYSTEM) dont voici ci-dessous le contenu. Il ne faut pas attacher d'importance pour l'instant au fait que certaines entités sont déclarées avec un caractère %. Nous allons éclairer ce point un peu plus loin.
Toutes les entités de ce document sont des entités internes à l'exception des deux premières, nommée HTMLlat1 et reponse, qui sont des entités externes.
<?xml version="1.0" encoding="UTF-8"?>
<!ENTITY % HTMLlat1 PUBLIC
"-//W3C//ENTITIES Latin 1 for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent">
%HTMLlat1;
<!ENTITY reponse SYSTEM "reponse.txt">
<!ENTITY oelig "œ">
<!ENTITY lui "un gars">
<!ENTITY elle "sa sœur">
<!ENTITY % Auteur "auteur CDATA #REQUIRED" >
<!ENTITY % Mode "mode (chaleureux|indifférent|distant|froid) 'indifférent'" >
<!ENTITY % Attributs "%Mode; %Auteur;" >
<!ELEMENT echange (salutations, reponse)*>
<!ELEMENT salutations (#PCDATA)>
<!ELEMENT reponse (#PCDATA)>
<!ATTLIST salutations
%Attributs;
id ID #REQUIRED
>
<!ATTLIST reponse
%Attributs;
>
Les entités externes référencent un contenu qui est externe au document (fichier local ou URI sur le réseau). Comme nous l'avons vu pour les DTD elles-mêmes, les entités externes peuvent être soit SYSTEM, soit PUBLIC.
Pour une entité externe SYSTEM, le mot clé SYSTEM précède la référence de l'entité dans sa déclaration et on précise uniquement l'uri d'un fichier (soit dans le système de fichiers local, soit sur le web). C'est le cas de l'entité nommée reponse dans l'exemple ci-dessus. Voici d'ailleurs le contenu du fichier référencé par cette entité :
<reponse auteur="&elle;">
" À toi aussi, merci. "
</reponse>
Pour une entité externe PUBLIC, on rajoute devant l'uri (facultatif) du document référencé un identifiant public construit sur les mêmes règles que l'identifiant public d'une DTD (voir plus haut). Ainsi, l'exemple ci-dessus intègre le document identifié par "-//W3C//ENTITIES Latin 1 for XHTML//EN" qui, comme son nom l'indique comporte un certain nombre de déclarations d'entités utiles dans le jeu de caractères Latin1.
On pourra télécharger ce document et le consulter à l'adresse http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent.
Remarques :
Une entité générale peut être utilisée indifféremment soit dans la DTD dans laquelle elle est déclarée, soit dans le document XML régi par cette DTD.
Pour utiliser une entité générale, on encadre son nom par une éperluette (&) et un point-virgule.
Exemples : &lui; , œ , etc...
Elles sont destinées à simplifier l'écriture des DTD en permettant la factorisation d'un certain nombre de tournures communes.
Remarques préalables :
La DTD ci-dessus comporte un certain nombre d'entités paramétriques. Ainsi, les entités paramétriques %Mode; et %Auteur; sont utilisées dans la défintion de l'entité paramétrique &Attributs; qui elle-même sera utilisée deux fois : une fois pour déclarer les attributs de l'élément salutations et une autre fois pour déclarer les mêmes attributs pour l'élément reponse. Noter que l'on a rajouté ensuite un attribut suplémentaire à l'élément salutations par rapport à l'élément reponse.
Télécharger les trois fichiers visualisés ci-dessus (echange.xml, echange.dtd et reponse.txt) puis vérifier la validité du document XML par rapport à sa DTD.
La technique des entités paramétriques est très abondamment utilisée dans les DTD d'HTML ou XHTML pour ce qui est de la déclaration des attributs. Ainsi, on trouve par exemple dans la DTD de XHTML1 transitional la définition suivante :
<!ENTITY % coreattrs "id ID #IMPLIED class CDATA #IMPLIED style %StyleSheet; #IMPLIED title %Text; #IMPLIED" >
Cette définition utilise elle-même les entités texte paramétriques nommées StyleSheet et Text dont voici la définition :
<!ENTITY % StyleSheet "CDATA"> <!ENTITY % Text "CDATA">
Un peu plus loin dans le même document, on trouve la définition de l'élément br avec sa liste d'attributs :
<!ELEMENT br EMPTY>
<!-- forced line break -->
<!ATTLIST br
%coreattrs;
clear (left|all|right|none) "none"
>
Cette définition dit que l'élément br est nécessairement vide (il ne peut donc contenir d'autres éléments), qu'il dispose de tous les attributs définis dans le groupe d'attributs coreattrs (à savoir id, class, style et title) plus l'attribut clear dont la valeur par défaut est none.
Tous les autres éléments XHTML disposent ainsi des attributs du groupe coreattrs.
On voit que ces attributs paramétriques ne sont pas faits pour être utilisés dans le document XML lui-même, mais uniquement dans la DTD où ils permettent de regrouper les déclarations d'attributs.
Les DTD sont des outils très performants pour décrire la structure d'un document XML, mais elle ne parlent guère beaucoup de leur contenu.
Impossible par exemple de spécifier que la valeur de tel attribut doit être de type entier, que tel autre doit être une chaîne de caractères, etc.
Par ailleurs, un reproche essentiel que l'on peut faire aux DTD est ... que ce ne sont pas des documents XML !
Contrairement aux DTD, XML Schema, qui est venu prendre la relèvre des DTD en octobre 2000, possède les caractéristiques suivantes :
XML Schema n'est donc rien d'autre que l'un des nombreux langages que l'on peut créer grâce au méta-langage XML. La syntaxe précise de ce langage est définie, non pas dans une DTD, mais dans un document XML-Schema : il s'agit donc là d'une définition récursive...
Un exemple de schéma XML :
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="personne">
<xs:complexType>
<xs:sequence>
<xs:element name="nom" type="xs:string"/>
<xs:element name="prenom" type="xs:string"/>
<xs:element name="date_naissance" type="xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
Nous n'étudierons pas davantage les schémas XML dans le cadre de ce cours. Le lecteur intéressé pourra se reporter à la recommandation correspondante du W3C dont on trouve la traduction française sur le site http://xmlfr.org/w3c/TR/xmlschema-0/.
A titre d'information, voici la version XML-Schéma du document echange.xml utilisé plus haut et voici le schéma correspondant. On pourra vérifier la validité du document XML par rapport à son schéma.
Tout document XML peut contenir les cinq types de composants suivants :
| Type de composant | Délimité par |
|---|---|
| Déclarations de type de document | <:DOCTYPE nom [ ... ]> |
| Éléments | <balise> ... </balise> |
| Parties CDATA (Character Data) | <![CDATA{ ... ]]> |
| Commentaires | <!--- ... --> |
| Instructions de traitement | <? ... ?> |
Ils débutent par <!-- et se terminent par -->.
Les données caractères situées dans des commentaires ne sont pas analysées : on peut donc y inclure toutes sortes de caractères y compris &, <, >, les guillemets ou les apostrophes.
À noter toutefois que la chaîne de caractères -- est interdite dans un commentaire (sauf pour en signaler la fin, dans l'expresion -->).
Ils débutent par <?nom_de_l_instruction et se terminent par ?>.
Elles ne sont pas analysées non plus par les parseurs : elles servent à invoquer une application autre que le processeur XML pour effectuer un traitement sur tout ou partie du document XML.
Nous utiliserons par exemple des intructions de traitement pour provoquer la transformation du document XML en lui appliquant une feuille de style XSLT.
Nous avons également déjà rencontré une instruction de traitement dans le chapitre sur CSS lorsque nous avons associer une feuille de style CSS à un document XML :
<?xml version="1.0" encoding="iso-8859-1"?>
<?xml-stylesheet type="text/css" href="bach2.css"?>
<ARTICLE>
<HEADLINE>La rencontre de Frédéric le Grand et de Bach</HEADLINE>
<AUTHOR>Johann Nikolaus Forkel</AUTHOR>
<PARA>
Un soir, alors qu'il préparait sa
<INSTRUMENT>flûte</INSTRUMENT> et que ses
musiciens étaient réunis, un officier lui apporta
la liste des étrangers qui venaient d'arriver.
</PARA>
</ARTICLE>
Elles débutent par <![CDATA[ et se terminent par ]]>.
Elles non plus ne sont pas analyées. Elles sont utiles lorsqu'un élément doit contenir une grand nombre de caractères spéciaux qui nécessiteraient sans cela un recours intensif aux entités.
Ainsi, imaginons que l'on veuille écrire un programme Java dans un élément XML. De nombreuses instructions contiendront alors des caractères interdits :
while (a<b && b>a) a=t[a];
Il est alors plus simple d'inclure tout le programme dans une section CDATA dans laquelle ces caractères ne poseront pas de problèmes :
<![CDATA[
while (a<b && b>a) a=t[a];
]]>
Il faut cependant se méfier d'instructions telles que :
if (t[t[i]]>5) return;
car le parseur y détecterait la fin de la section CDATA imédiatement après le caractère i.
Une solution consiste à séparer les deux crochets par des espaces ou à les inclure dans deux sections CDATA différentes.
Supposons que nous souhaitions créer un langage XML de description d'un cours. Un document rédigé dans cet hypothétique langage serait par exemple le suivant :
<?xml version="1.0" encoding="ISO-8859-1"?>
<cours>
<title>
NFE102 - Infrastructures technologiques pour le Commerce Électronique
</title>
<table>
<chapter num="1">HTML</chapter>
<chapter num="2">CSS</chapter>
<chapter num="3">DOM</chapter>
</table>
</cours>
Nous savons déjà que nous pouvons visualiser un tel document dans un navigateur en lui rajoutant une feuille de styles CSS (utiliser Firefox ou Mozilla, car Internet Explorer ne va pas justement pas gérer correctement les espaces de noms).
Pour l'occasion, nous allons intégrer cette feuille de style dans le document lui-même en ajoutant un élément style comme nous le ferions dans une page HTML.
Problème :
Solution :
La solution consiste à créer deux espaces de noms distincts pour chaque langage ainsi les éléments qui feront partie de deux espaces différents ne pourront pas être confondus.
Un espace de noms est toujours associé à un URI (Universal Resource Identifier, en fait une adresse web), mais il n'est pas nécessaire que cette adresse existe réellement. Dans la deuxième version de notre document, nous allons dire que tous les éléments de notre langage sont dans l'espace de noms associé à l'uri http://ouest.pleiad.net. Il suffit pour cela de le préciser grâce à l'attribut xmlns (pour XML Name Space) de la racine du document (attention, Mozilla ou FireFox ne montre pas la valeur de cet attribut) :
<?xml version="1.0" encoding="ISO-8859-1"?>
<cours xmlns="http://ouest.pleiad.net">
<title>
NFE102 - Infrastructures technologiques pour le Commerce Électronique
</title>
<table>
<chapter num="1">HTML</chapter>
<chapter num="2">CSS</chapter>
<chapter num="3">DOM</chapter>
</table>
</cours>
De cette façon, les éléments title et table font partie de l'espace de noms que nous avons créé.
Nous pouvons maintenant ajouter des éléments de l'espace de noms associé à HTML sans risquer qu'ils soient confondus avec les nôtres. Il nous suffit pour cela de connaître l'uri associé à cet espace de noms (il figure dans n'importe quel document HTML bien écrit, il s'agit par exemple de http://www.w3.org/1999/xhtml).
Il reste un problème : comment allons distinguer les éléments de l'un ou de l'autre espace de noms ?
Pour cela, nous allons faire correspondre à un espace de noms donné un préfixe que nous utiliserons pour préfixer les éléments de cet espace.
Ainsi, dans la troisième version de notre document, nous avons déclaré que nous voulons marquer par le préfixe html les éléments de l'espace de noms associé à http://www.w3.org/1999/xhtml.
<?xml version="1.0" encoding="ISO-8859-1"?>
<cours xmlns="http://ouest.pleiad.net" xmlns:html="http://www.w3.org/1999/xhtml">
<title>
NFE102 - Infrastructures technologiques pour le Commerce Électronique
</title>
<table>
<chapter num="1">HTML</chapter>
<chapter num="2">CSS</chapter>
<chapter num="3">DOM</chapter>
</table>
</cours>
Regardez bien les deux déclarations d'espaces de noms : elles n'ont pas la même forme. La première définit l'espace de noms par défaut (il n'y a donc pas de préfixe), la seconde définit non seulement un espace de noms, mais aussi le préfixe html qui lui sera associé.
Ainsi, nous pouvons maintenant ajouter par exemple un élément html:title dans notre document : il ne sera pas confondu avec notre élément title existant :
<?xml version="1.0" encoding="ISO-8859-1"?> <cours xmlns="http://ouest.pleiad.net" xmlns:html="http://www.w3.org/1999/xhtml">
<html:title>Contenu du cours</html:title> <title> NFE102 - Infrastructures technologiques pour le Commerce Électronique </title> <table> <chapter num="1">HTML</chapter> <chapter num="2">CSS</chapter> <chapter num="3">DOM</chapter> </table> </cours>
Si nous regardons l'exemple cette dernière version avec Mozilla ou FireFox, nous constaterons que notre but a bien été atteint : l'élément html:title n'a pas été confondu avec l'élément title ; le contenu du premier se retrouve effectivement dans le titre de la fenêtre tandis que le contenu du second est affiché dans la fenêtre.
Nous pouvons maintenant continuer en ajoutant un élément html:style qui contiendra le style CSS du document. Mais il nous faudra trouver un moyen de relier le document à cette feuille de style, ce sera le rôle de l'instruction de traitement que nous ajoutons en ligne 2 :
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/css" href="#mesStyles" ?> <cours xmlns="http://ouest.pleiad.net" xmlns:html="http://www.w3.org/1999/xhtml"> <html:style id="mesStyles"> * {display:block}
</html:style>
<html:title>Contenu du cours</html:title> <title> NFE102 - Infrastructures technologiques pour le Commerce Électronique </title> <table> <chapter num="1">HTML</chapter> <chapter num="2">CSS</chapter> <chapter num="3">DOM</chapter> </table> </cours>
Le résultat obtenu est différent sous Internet Explorer et Mozilla :
Les deux navigateurs distinguent correctement les espaces de noms et le titre de la fenêtre est correct dans les deux cas. Mais Internet Explorer considère que la règle * {display:block} ne s'applique qu'aux éléments de l'espace par défaut, tandis que Mozilla considére qu'ellle s'applique à tous les éléments (y compris les éléments title et style de l'espace HTML).
Comme souvent, c'est Mozilla qui a raison et qui nous offre en prime un moyen de distinguer les règles CSS par espaces de noms. Nous allons utiliser pour cela une règle-at nommée @namespace. Cette règle permet de faire correspondre un préfixe à un espace de noms et de préfixer ensuite les éléments avec ce préfixe. Ce dispositif est identique à celui décrit plus haut avec l'attribut xmlns, mais il est spécifique à CSS. À noter que le séparateur entre le préfixe et le nom de l'élément est ici une barre verticale à la place du double-point.
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/css" href="#mesStyles" ?> <cours xmlns="http://ouest.pleiad.net" xmlns:html="http://www.w3.org/1999/xhtml"> <html:style id="mesStyles">
@namespace cnam url('http://ouest.pleiad.net');
cnam|* {display:block}
cnam|title {color:red; font-family:arial; font-size:18pt; text-align:center;margin-bottom:2cm}
cnam|table {margin-left:40%}
</html:style>
<html:title>Contenu du cours</html:title> <title> NFE102 - Infrastructures technologiques pour le Commerce Électronique </title> <table> <chapter num="1">HTML</chapter> <chapter num="2">CSS</chapter> <chapter num="3">DOM</chapter> </table> </cours>
Nous pourrions continuer en utilisant n'importe quel élément HTML dans ce document (html:table, html:hr, etc...) pour la mise en page de notre document. Nous pourrions également définir des règles de style différentes pour les éléments de l'espace de noms HTML/
Modifier le document ci-dessus de manière à ce que les éléments chapter soient inclus dans des éléments html:li eux-mêmes contenus dans un élément html:ol.
Ajouter la règle de style suivante après avoir défini le préfixe html dans une règle-at adéquate :
html|ol {list-style-type: upper-roman;}
Il faut noter que la déclaration de l'espace de noms n'est pas nécessairement faite au niveau le plus élevé : en fait, la portée d'une telle déclaration est celle du contenu de l'élément possédant cet attribut.
Ceci signifie en particulier que tous les sous-éléments d'un tel élément hériteront de l'espace de noms correspondant.
Exemple : Dans le document ci-dessous, l'espace de noms "http://www.cnam.fr" contient les éléments racine, A et le deuxième élément C tandis que l'espace de noms "http://info.unicaen.fr" contient l'élément B et le premier des deux éléments C.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<racine mmlns="http://www.cnam.fr">
<A>
<B xmlns="http://info.unicaen.fr">
<C/>
</B>
<C/>
</A>
</racine>
Ceci vaut aussi pour les espaces de noms associés à un préfixe. En fait, ceux-ci ne sont guère différents des espaces de noms par défaut à ceici près que le préfixe est une chaîne vide pour ces derniers.
Notons que deux préfixes identiques peuvent éventuellement cohabiter dans le même document mais avec des espaces de noms associés différents, comme le montre l'exemple suivant :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<p:racine mmlns:p="http://www.cnam.fr">
<A>
<p:B xmlns:p="http://info.unicaen.fr">
<p:C/>
</p:B>
<p:C/>
</A>
</racine>
Dans le document ci-dessus, nous distinguons trois espaces de noms :
Déterminer l'espace de noms de chaque élément du document ci-dessous :
<?xml version="1.0" encoding="UTF-8"?>
<root>
<table xmlns="http://www.w3.org/1999/xhtml" border="1">
<tr><td>Nom</td><td>Adresse</td></tr>
<tr>
<td> <hr xmlns="">auteur : </hr> Hugo </td> <td>Paris</td>
</tr>
</table>
</root
Nous avons déjà étudié le Modèle Objet de Document (DOM) à l'occasion des pages HTML ou XHTML.
La représentation arborescente d'un document XML est simplement un arbre respectant les spécificatiopns du DOM.
Rappelons-en rapidement l'essentiel.
Il existe plusieurs types de nœuds dans un arbre DOM. Les différents types de nœuds sont :
Il existe deux types de parseurs capable de parcourir l'arborescence d'un document XML sérialisé :
Un parseur DOM va construire intégralement en mémoire l'arbre du document et va permettre ensuite au programmeur d'atteindre n'importe quel nœud de cet arbre à l'aide des fonctions de l'API du DOM (voir le cours correspondant).
Un parseur SAX va parcourir le document XML en déclenchant un certain nombre d'évènements tels que "début d'élément" ou "fin d'élément" par exemple, à charge pour le programmeur de fournir les procédures qui seront déclenchées par ces évènements.
L'intérêt d'un parseur SAX par rapport aux parseurs DOM est qu'il a besoin de beaucoup moins de mémoire puisque le document n'est pas représenté dans la mémoire. L'inconvénient est que le traitement doit se faire au fur et à mesure que les évènements surviennent et dans l'ordre dans lequel les éléments figurent dans le document sérialisé.
Voir les exercices de TP pour des exemples concrets.